难度:中等
听我说🦀🦀你,因为有你,山河更美丽3 次解出,455 pts
一血:l4n 二血:cfbb 三血:BKBQWQ
出题人认为 CTF 中的逆向从来不应该是为了折磨选手,而是让选手了解到某种程序实现的底层原理,在反复考虑难度后决定给出含完整函数名的 PDB 调试信息(WP 后面附有源码,可供对比观察)。
直接运行并观察输出,可猜测把输入的 flag 转换成了 emoji 字符串。往逆向里塞 emoji 是因为 Rust 有保证 Unicode 字符正确转换的语言特性,这部分没有任何 Misc 知识点,可以把这种字符串完全当作抽象的 “结构化数据流”,转换过程只是简单的四则运算和位运算。(WP 后附有用到的 Unicode 转换细节,供感兴趣的读者查阅。)
方便起见,下文
i32表示 32 位有符号整数,u8表示 8 位无符号整数,以此类推。
# 完整分析过程
先运行一下,发现必须要输入至少 48 字符才会得到结果,会输出 88 个 emoji;
输入相同时输出也相同;
尝试改变输入,如果改变最后一个字符会使后面大约一半的 emoji 发生变化;如果改变第一个字符会使全部 emoji 发生变化
附件确实给了 pdb,记得按 Yes
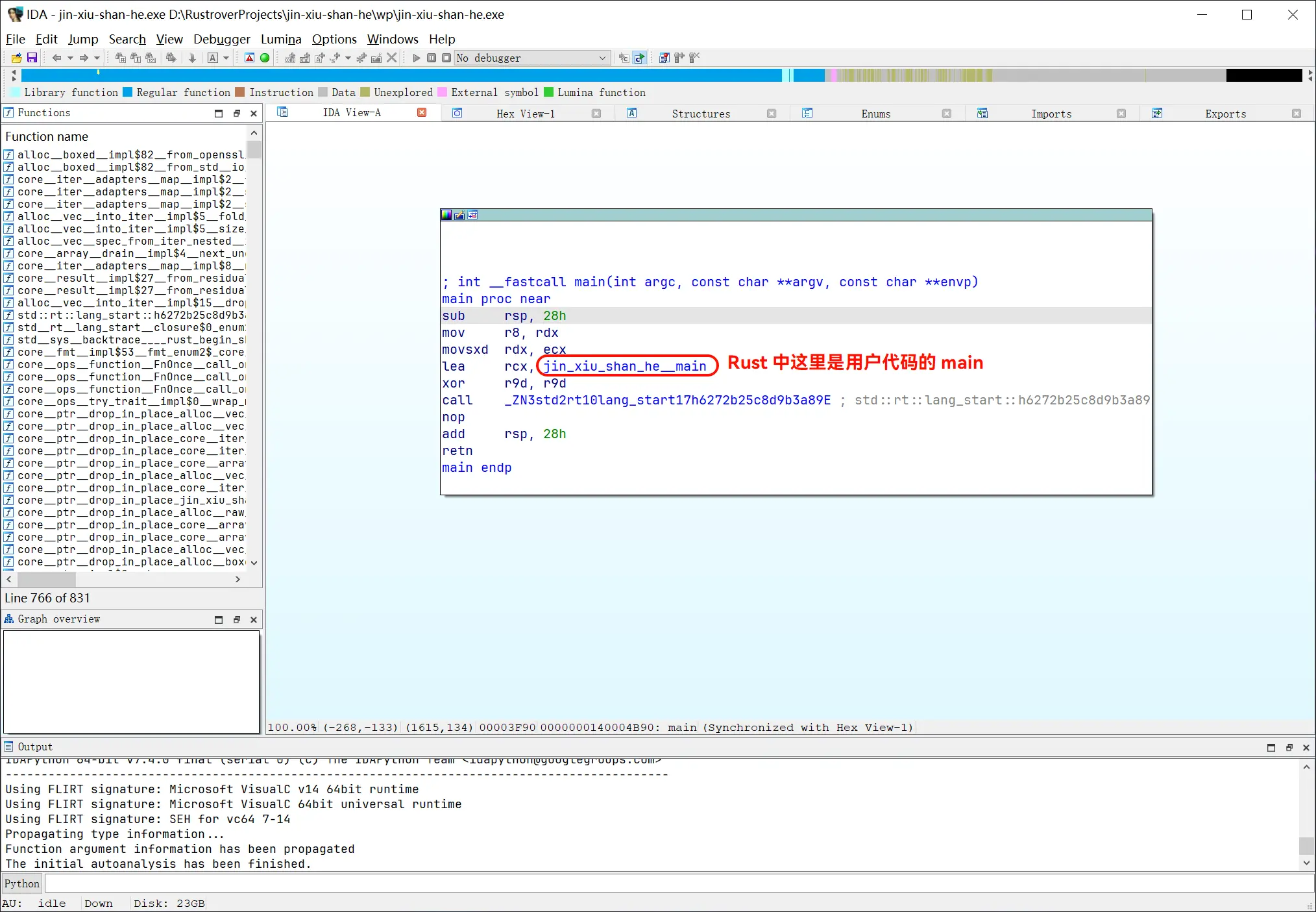
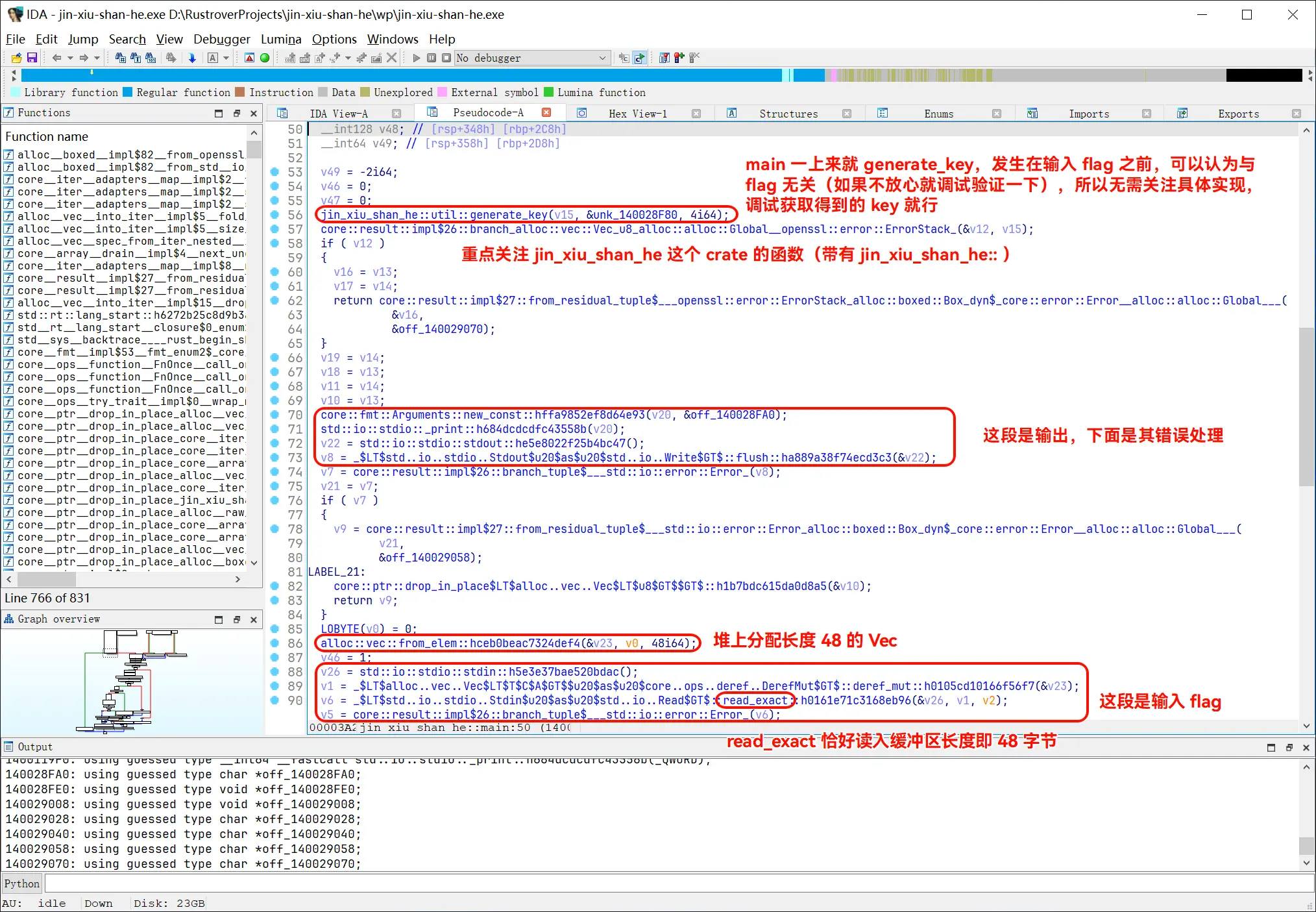
先看 main:
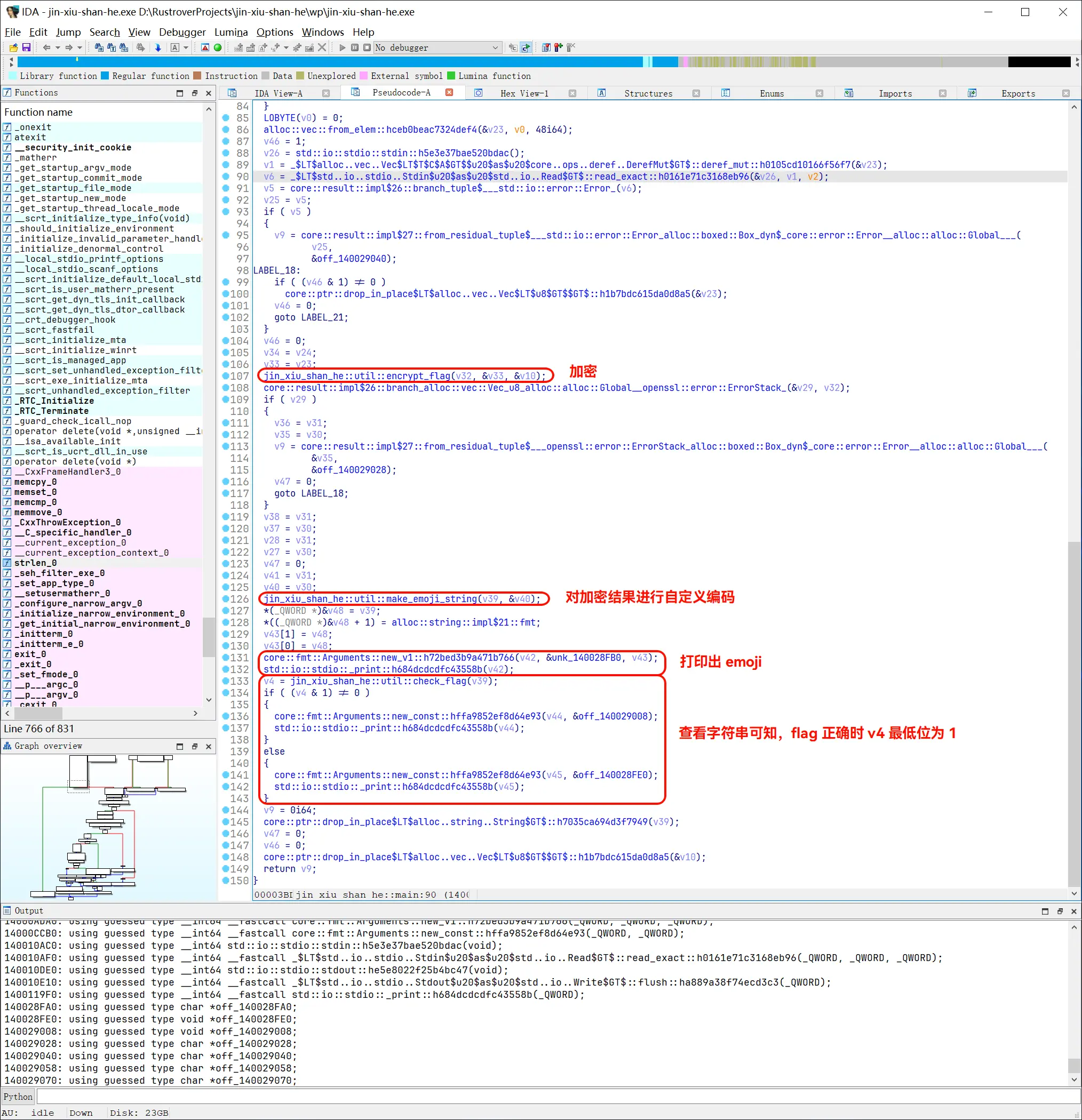
在 IDA 中显示正确的字符编码:
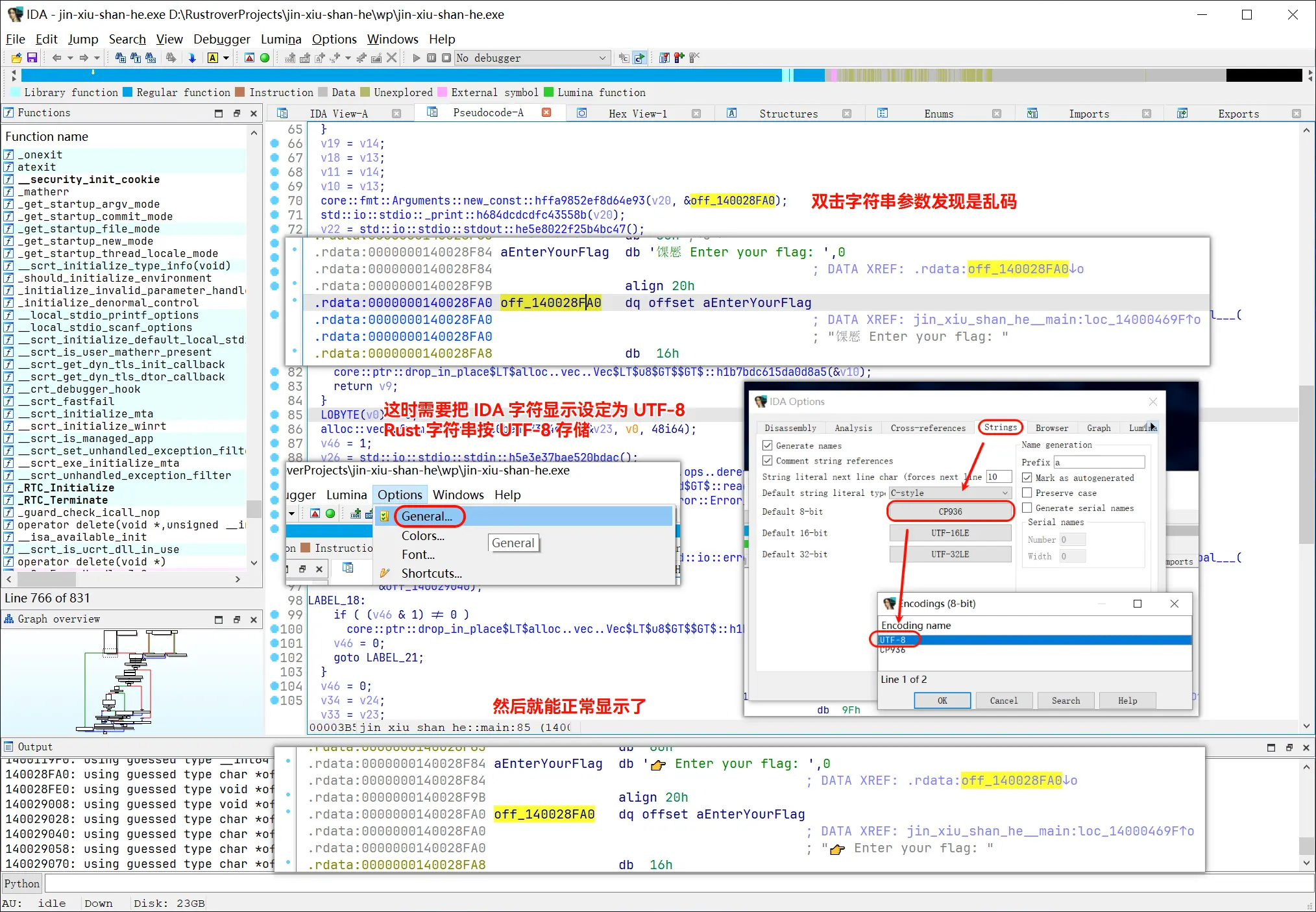
调试获取 key:
启动调试时弹出计算器文件内容,是因为出题人把 pdb 里源文件路径改成了
C:\Windows\System32\.\.\.\.\.\.\.\.\.\.\calc.exe
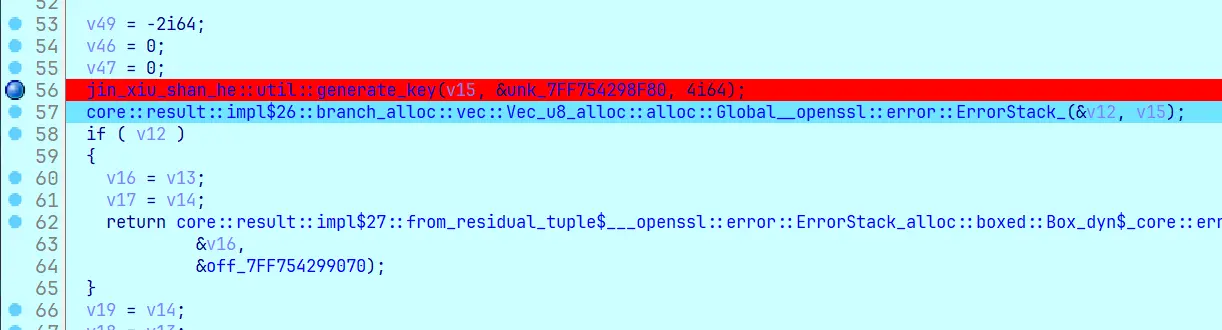
Rust 编译产物中经常出现这种情况:如果返回类型的大小大于 usize,第一个参数(v15)是 “调用方”(main)的栈上地址,“被调用方”(generate_key)往这个地址写返回类型的结构体。也就是说,v15 是作为返回值用的。
第 57 行的函数名能看出返回类型: Result<Vec<u8>, openssl::error::ErrorStack>
这是 Rust 中的 Result 枚举,它有两种枚举成员 Ok 或 Err。 Ok 成员表示操作成功,内部包含成功时产生的值。 Err 成员则意味着操作失败,并且 Err 中包含有关操作失败的原因或方式的信息。
第 58 行检查枚举值,如果不为 Ok,则提前结束 main,传播错误给 main 的调用方。
双击 v15 查看数据(原本看到的是字节,已按 R 键设为 64 位整数):

本次调试中 24D40BE31A0 处的 16 字节就是 key:
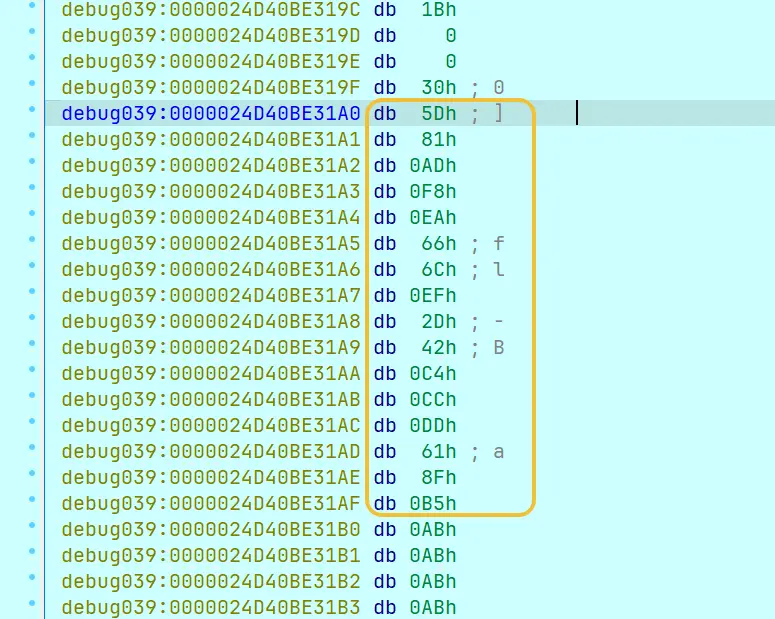
同理这是 main 第 86 行分配给输入的 Vec:
(写 WP 过程中有多次重新开始调试,部分地址可能前后不一致,敬请谅解)

控制流不好跟踪的话,可以尝试跟踪数据流。在输入后,对这段内存打上读写断点:
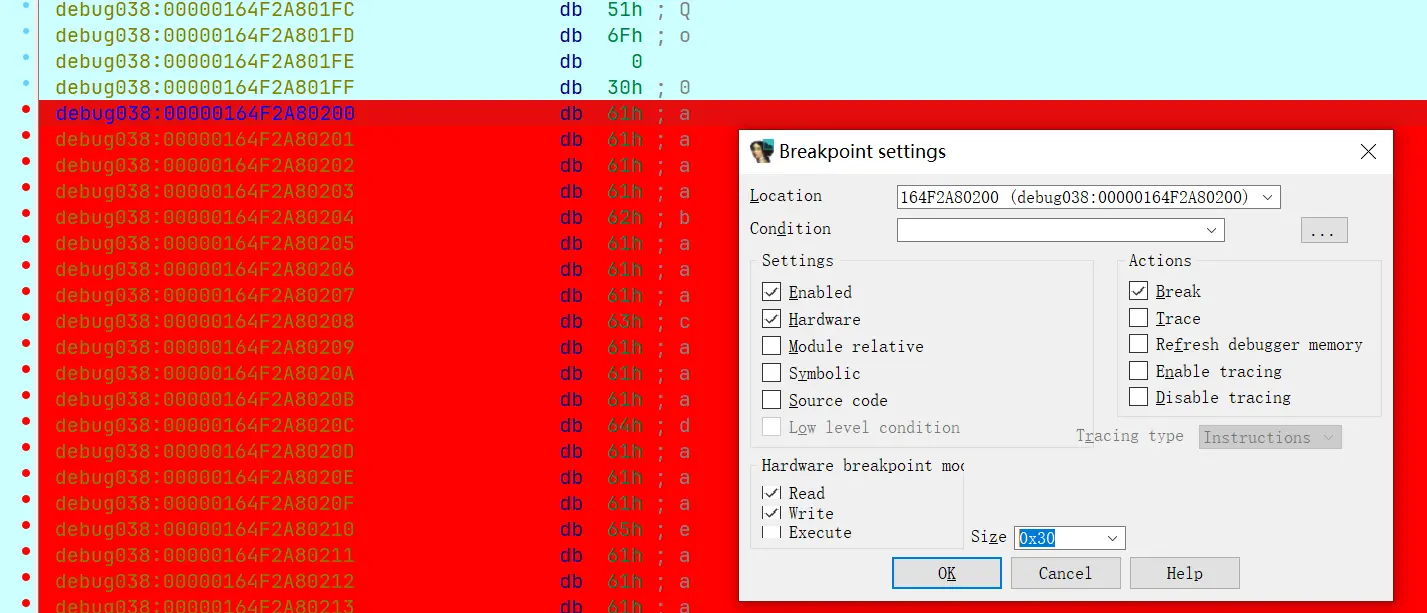
调试发现 encrypt_flag 的参数分别为:


Rust 的标准库和第三方库(crate)基本都是源码分发的,也可以查到文档:
https://docs.rs/openssl/0.10.68/openssl/symm/fn.encrypt.html
返回的同样也是一个 Result 枚举,同样打上内存断点(就不截图了):

分组密码长度扩展时确实会补 1~16 个字节并达到 16 的倍数,所以明文的 48 字节变成了 64 字节。
值得一提的是,encrypt_flag 取得了原本输入的 Vec 的所有权,并最后 drop 了它。
回到 main。接下来是 make_emoji_string:

第 75 行点进去 10 层函数调用 (不是出题人故意的,它编译后就长这样),可以看到 jin_xiu_shan_he::util::make_emoji_string::closure$0 函数把前面 Base64 得到的 0~63 按位或了 0x1F600,于是映射到了这个范围:
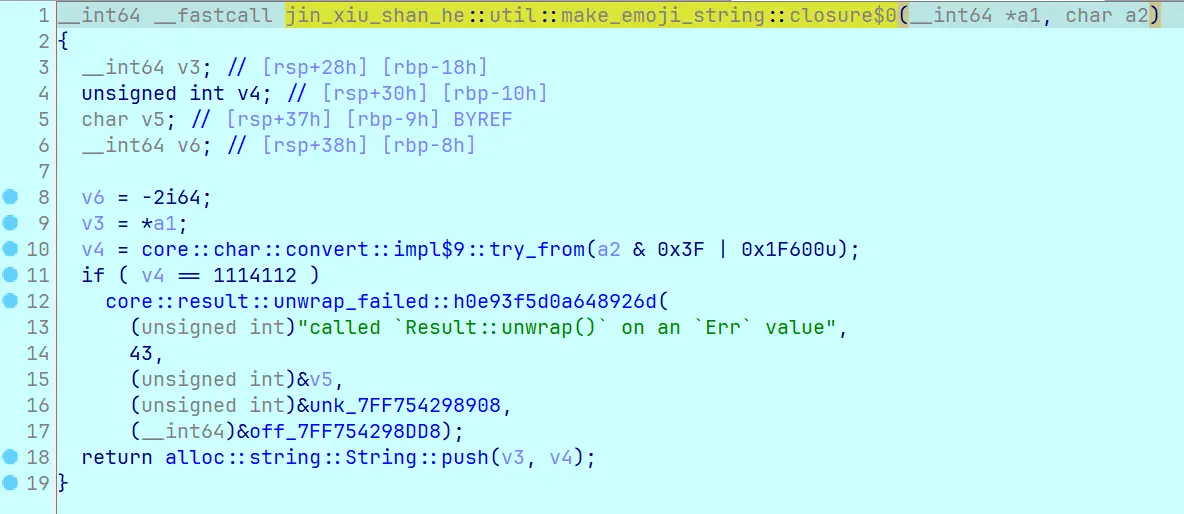

第 18 行的 String::push 把这个 char 转成 UTF-8 放到可变字符串里。
回到 main。最后是 check_flag:
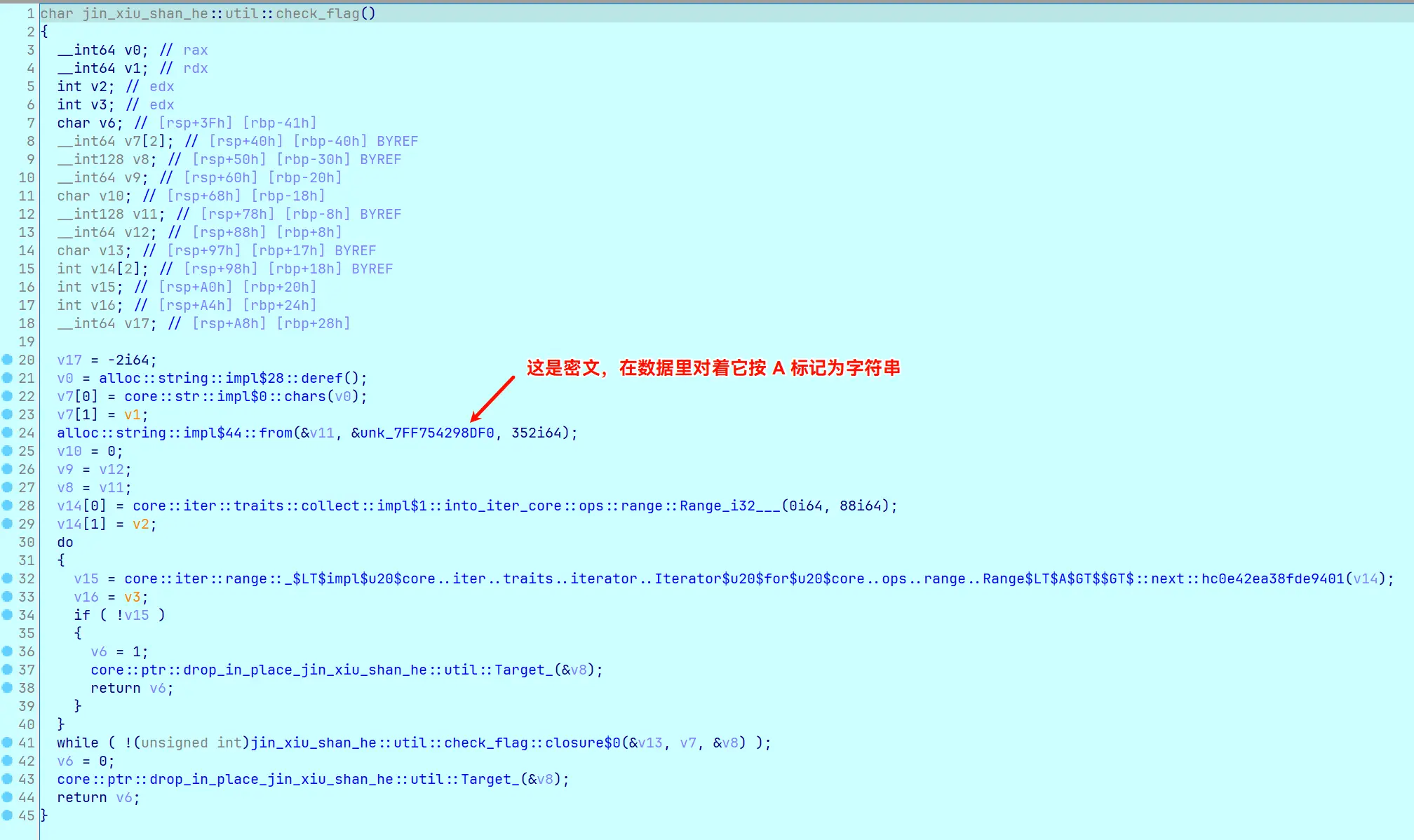


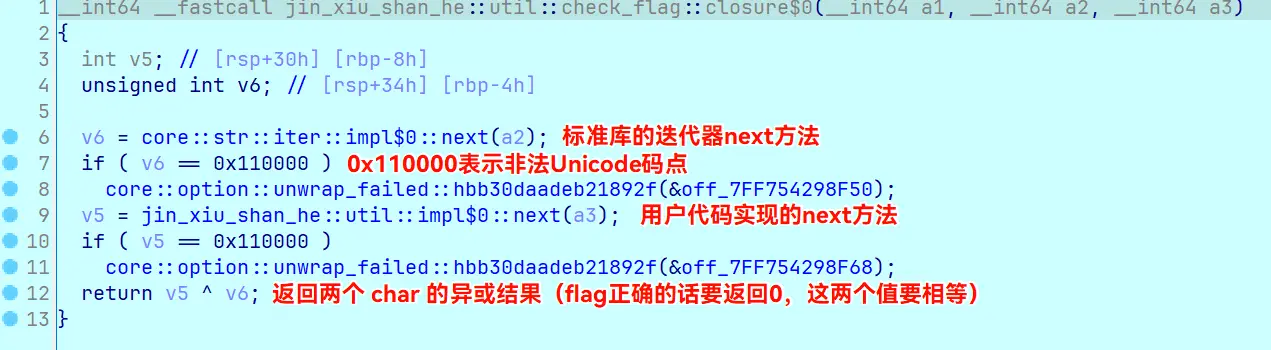
如果在这时尝试提取密文数据解密,会无法解码 SM4 或得到乱码。这是因为每迭代一次,在 jin_xiu_shan_he::util::impl$0::next 中会把整段密文修改一次。在做题时可能不容易发现这一点,但是如果对密文数据打了内存断点,会发现在 next 中它已被析构回收。
这时有两种做法,可以分析 next 函数的实现:
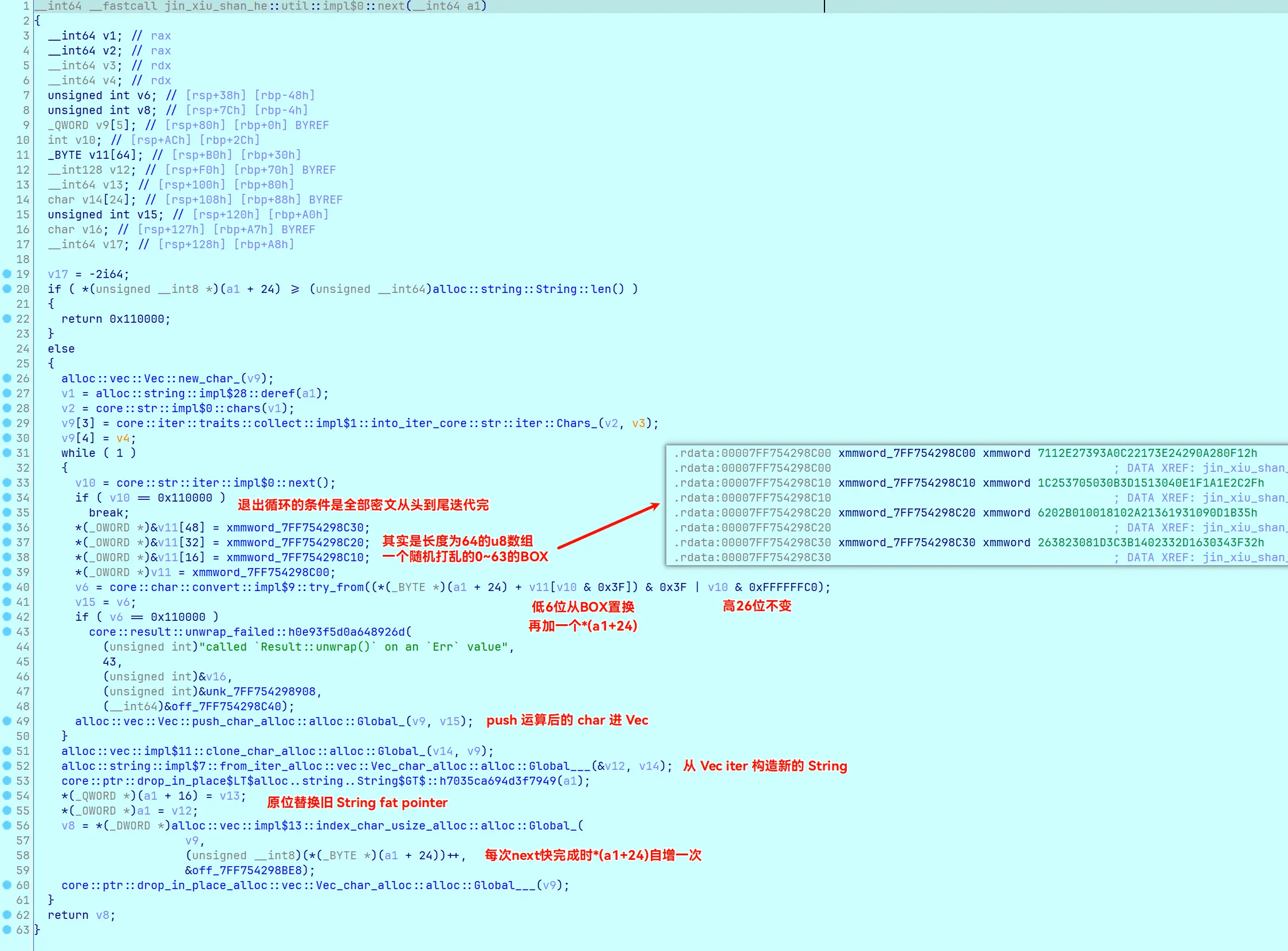
也可以不考虑对密文的具体处理 (前提是其与输入无关,可通过内存断点验证),只在每次比对时,记录下处理后的密文:

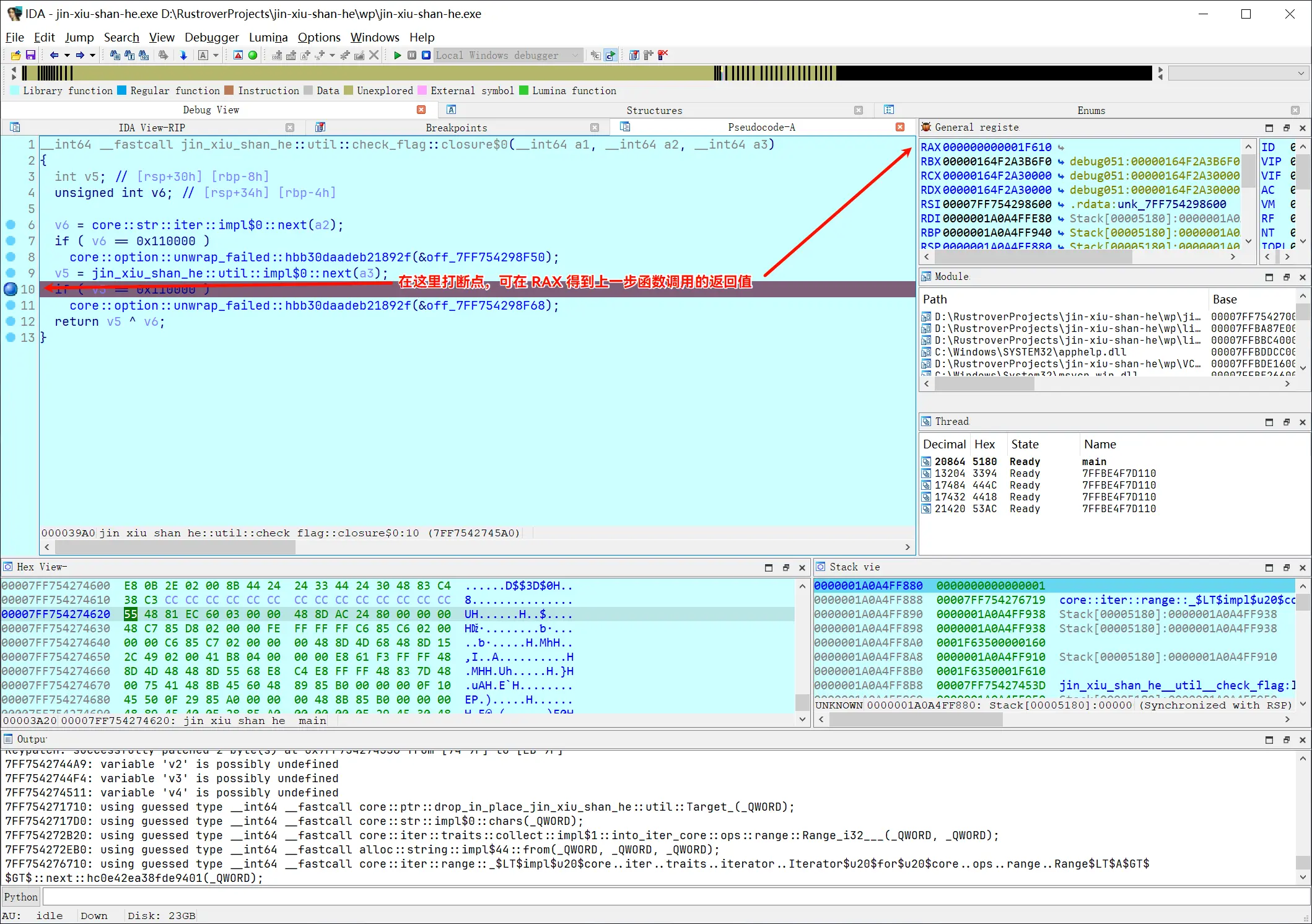
每点一下运行,就会停在这里一次,可以手动记录下一个正确的密文。(我的附件第一次是 0x1F610)
也可用 IDAPython 将其输出:
import ida_dbg | |
print(hex(ida_dbg.get_reg_val("eax")), end=', ') |
也可尝试精心 patch,使得正确的密文被按序写入内存,然后一次性提取。
# 解密脚本
如果是「记录处理后的密文」做法:
from gmssl import sm4 | |
KEY = bytes([93, 129, 173, 248, 234, 102, 108, 239, 45, 66, 196, 204, 221, 97, 143, 181]) | |
enc = [ | |
0x1F610, 0x1F603, 0x1F627, 0x1F617, 0x1F612, 0x1F605, 0x1F63E, 0x1F617, | |
0x1F630, 0x1F606, 0x1F625, 0x1F600, 0x1F60F, 0x1F62B, 0x1F61A, 0x1F60E, | |
0x1F616, 0x1F61C, 0x1F613, 0x1F63A, 0x1F60E, 0x1F626, 0x1F631, 0x1F632, | |
0x1F634, 0x1F61B, 0x1F606, 0x1F623, 0x1F604, 0x1F60F, 0x1F62E, 0x1F604, | |
0x1F63C, 0x1F619, 0x1F607, 0x1F629, 0x1F601, 0x1F607, 0x1F609, 0x1F637, | |
0x1F602, 0x1F632, 0x1F634, 0x1F635, 0x1F61C, 0x1F62D, 0x1F612, 0x1F617, | |
0x1F61A, 0x1F62B, 0x1F62F, 0x1F610, 0x1F619, 0x1F62A, 0x1F63C, 0x1F616, | |
0x1F609, 0x1F634, 0x1F62E, 0x1F639, 0x1F611, 0x1F62E, 0x1F630, 0x1F623, | |
0x1F608, 0x1F616, 0x1F608, 0x1F63C, 0x1F604, 0x1F61D, 0x1F618, 0x1F619, | |
0x1F635, 0x1F63C, 0x1F632, 0x1F63D, 0x1F605, 0x1F635, 0x1F61B, 0x1F603, | |
0x1F60A, 0x1F60B, 0x1F636, 0x1F603, 0x1F63F, 0x1F600, 0x1F600, 0x1F600, | |
] | |
enc_target = [c & 0x3F for c in enc] # 高位不影响解密,只取低 6 位 | |
sm4_enc = [] | |
for i in range(0, len(enc_target), 4): # Base64 解码 | |
d = enc_target[i:i + 4] | |
sm4_enc.extend([ | |
(d[0] << 2 | d[1] >> 4) & 0xFF, | |
(d[1] << 4 | d[2] >> 2) & 0xFF, | |
(d[2] << 6 | d[3]) & 0xFF, | |
]) | |
sm4_enc = sm4_enc[:64] # 去掉末尾的两个 0 | |
sm4_instance = sm4.CryptSM4(mode=sm4.SM4_DECRYPT) | |
sm4_instance.set_key(KEY, sm4.SM4_DECRYPT) | |
flag = sm4_instance.crypt_cbc(reversed(KEY), bytes(sm4_enc)).decode() | |
print(flag) |
如果是「分析对密文的处理」做法:
from gmssl import sm4 | |
KEY = bytes([93, 129, 173, 248, 234, 102, 108, 239, 45, 66, 196, 204, 221, 97, 143, 181]) | |
BOX = [ | |
18, 15, 40, 10, 41, 36, 62, 23, 34, 12, 58, 57, 39, 46, 17, 7, | |
47, 44, 30, 26, 31, 14, 4, 19, 21, 61, 11, 3, 5, 55, 37, 28, | |
53, 27, 13, 9, 49, 25, 54, 33, 42, 16, 24, 0, 1, 43, 32, 6, | |
50, 63, 52, 48, 22, 45, 51, 2, 20, 59, 60, 29, 8, 35, 56, 38 | |
] | |
emojis = '😩😝😹😒😟😱😘😌😎😟😭😼😑😯😀😍😨😖😍😮😗😗😘😽😠😻😱😗😉😏😈😀😿😷😗😴😠😧😻😹😚😯😤😥😪😅😩😬😼😰😁😝😐😧😵😍😅😪😝😼😃😂😾😕😷😛😎😷😊😙😠😁😸😕😪😬😓😹😾😝😇😇😭😎😩😳😟😷' | |
emojis = [ord(c) & 0x3F for c in emojis] # 高位字节不影响解密,只取低 6 位 | |
enc_target = [] | |
for i in range(88): | |
cur = emojis[i] & 0x3F | |
for j in range(i + 1): # 第 i 个 emoji 在被返回前,修改了 i+1 次 | |
cur = BOX[cur] | |
cur = (cur + j) & 0x3F | |
enc_target.append(cur) | |
sm4_enc = [] | |
for i in range(0, len(enc_target), 4): # Base64 解码 | |
d = enc_target[i:i + 4] | |
sm4_enc.extend([ | |
(d[0] << 2 | d[1] >> 4) & 0xFF, | |
(d[1] << 4 | d[2] >> 2) & 0xFF, | |
(d[2] << 6 | d[3]) & 0xFF, | |
]) | |
sm4_enc = sm4_enc[:64] # 去掉末尾的两个 0 | |
sm4_instance = sm4.CryptSM4(mode=sm4.SM4_DECRYPT) | |
sm4_instance.set_key(KEY, sm4.SM4_DECRYPT) | |
flag = sm4_instance.crypt_cbc(reversed(KEY), bytes(sm4_enc)).decode() | |
print(flag) |
# 附源码
cargo.toml
[package] | |
name = "jin-xiu-shan-he" | |
version = "0.1.0" | |
edition = "2021" | |
[dependencies] | |
openssl = "0.10.68" | |
[profile.release] | |
opt-level = 0 | |
debug = "limited" |
采用 release 配置文件, opt-level = 0 是反复考虑难度后决定不让标准库函数(例如 UTF-8 转 char)内联影响分析, debug = "limited" 是为了保留用户代码的函数名,但不保留变量类型。
main.rs
mod util; | |
use std::error::Error; | |
use std::io::{self, Read, Write}; | |
fn main() -> Result<(), Box<dyn Error>> { | |
let key = util::generate_key(b"\xF0\x9F\xA6\x80")?; | |
// [93, 129, 173, 248, 234, 102, 108, 239, 45, 66, 196, 204, 221, 97, 143, 181] | |
print!("👉 Enter your flag: "); | |
io::stdout().flush()?; | |
let mut flag = vec![0u8; 48]; | |
io::stdin().read_exact(&mut flag)?; | |
let enc = util::encrypt_flag(flag, &key)?; | |
let enc = util::make_emoji_string(enc); | |
println!("{}", enc); | |
if util::check_flag(&enc) { | |
println!("🥳 You got it!"); | |
} else { | |
println!("🤯 Try again!"); | |
} | |
Ok(()) | |
} |
util.rs
use std::str::Chars; | |
use openssl::error::ErrorStack; | |
use openssl::hash::{hash, MessageDigest}; | |
use openssl::symm::{encrypt, Cipher}; | |
struct Target(u8, String); | |
const BOX: [u8; 64] = [ | |
18, 15, 40, 10, 41, 36, 62, 23, 34, 12, 58, 57, 39, 46, 17, 7, 47, 44, 30, 26, 31, 14, 4, 19, | |
21, 61, 11, 3, 5, 55, 37, 28, 53, 27, 13, 9, 49, 25, 54, 33, 42, 16, 24, 0, 1, 43, 32, 6, 50, | |
63, 52, 48, 22, 45, 51, 2, 20, 59, 60, 29, 8, 35, 56, 38, | |
]; | |
const TARGET_EMOJIS: &str = "😷😯😞😻😞😊😏😡😷😅😉😙😜😤😮😘😑😮😨😭😬😺😒😊😙😳😎😧😜😡😝😜😶😤😤😸😫😳😦😴😿😈😫😹😑😨😽😒😡😦😧😺😷😖😐😶😘😭😞😠😑😁😧😮😣😮😳😄😣😗😦😑😝😭😛😱😯😄😍😒😻😠😝😂😮😳😟😷"; | |
impl Iterator for Target { | |
type Item = char; | |
#[inline(never)] | |
fn next(&mut self) -> Option<Self::Item> { | |
let len = self.1.len(); | |
if self.0 as usize >= len { | |
return None; | |
} | |
let mut new_string: Vec<char> = vec![]; | |
for c in self.1.chars() { | |
new_string.push( | |
char::try_from( | |
c as u32 & 0xFFFFFFC0 | |
| ((BOX[(c as u32 & 0x3F) as usize] + self.0) as u32 & 0x3F), | |
) | |
.unwrap(), | |
); | |
} | |
self.1 = String::from_iter(new_string.clone()); | |
self.0 += 1; | |
Some(new_string[(self.0 - 1) as usize]) | |
} | |
} | |
#[inline(never)] | |
pub fn generate_key(data: &[u8]) -> Result<Vec<u8>, ErrorStack> { | |
let mut data = Vec::from(data); | |
for _ in 0..202410 { | |
data = Vec::from(&*hash(MessageDigest::sha512(), &data)?) | |
.chunks(4) | |
.map(|x| x[0] ^ x[1] ^ x[2] ^ x[3]) | |
.collect(); | |
} | |
Ok(data) | |
} | |
#[inline(never)] | |
pub fn encrypt_flag(msg: Vec<u8>, key: &Vec<u8>) -> Result<Vec<u8>, ErrorStack> { | |
let mut iv = key.clone(); | |
iv.reverse(); | |
encrypt( | |
Cipher::sm4_cbc(), | |
key, | |
Some(&iv), | |
&msg, | |
) | |
} | |
#[inline(never)] | |
pub fn make_emoji_string(flag: Vec<u8>) -> String { | |
let mut v = String::new(); | |
for d in flag.chunks(3) { | |
let d = match d.len() { | |
1 => &[d[0], 0, 0], | |
2 => &[d[0], d[1], 0], | |
_ => d, | |
}; | |
[ | |
d[0] >> 2, | |
d[0] << 6 >> 2 | d[1] >> 4, | |
d[1] << 4 >> 2 | d[2] >> 6, | |
d[2] << 2 >> 2, | |
].map(|b| v.push(char::try_from(b as u32 & 0x3F | 0x1F600).unwrap())); | |
} | |
v | |
} | |
#[inline(never)] | |
pub fn check_flag(enc: &String) -> bool { | |
let mut iter = enc.chars(); | |
let mut target = Target(0, String::from(TARGET_EMOJIS)); | |
let xor = | |
|x: &mut Chars, y: &mut Target| x.next().unwrap() as u32 ^ y.next().unwrap() as u32; | |
for _ in 0..88 { | |
if xor(&mut iter, &mut target) != 0 { | |
return false; | |
} | |
} | |
true | |
} |
# 附用到的 Unicode 转换细节
这部分算 Misc,仅供感兴趣的师傅阅读。解本题时不需知道。
有的师傅可能注意到了,本题中 emoji 有时候表现为 0x1F6?? 的形式,有时候表现为 0xF09F98?? 的形式。
实际上前者为该码点在 Unicode 全表中从 0 开始的序号(这个表不是完全连续的),后者为 UTF-8 变长编码。

单个码点的编号用 u32 可以存得下,但是它不符合前缀码规则,不能放进字节数组当成字符串。
以🦪(U+1F9AA)为例,如果在数组中,它可以被解释为单个码点,也可以被解释为一个 0x1F9 和一个 0xAA,或者一个 0x1,一个 0xF9,一个 0xAA,等等。
1F9AA(11111 100110 101010)可以用以下变长编码(UTF-8)表示:
11110000 10011111 10100110 10101010
最前面的 11110 表示接下来这个字符占 4 个字节,如果是汉字(3 个字节)则最前面是 1110。后面每个字节都以 10 开头。
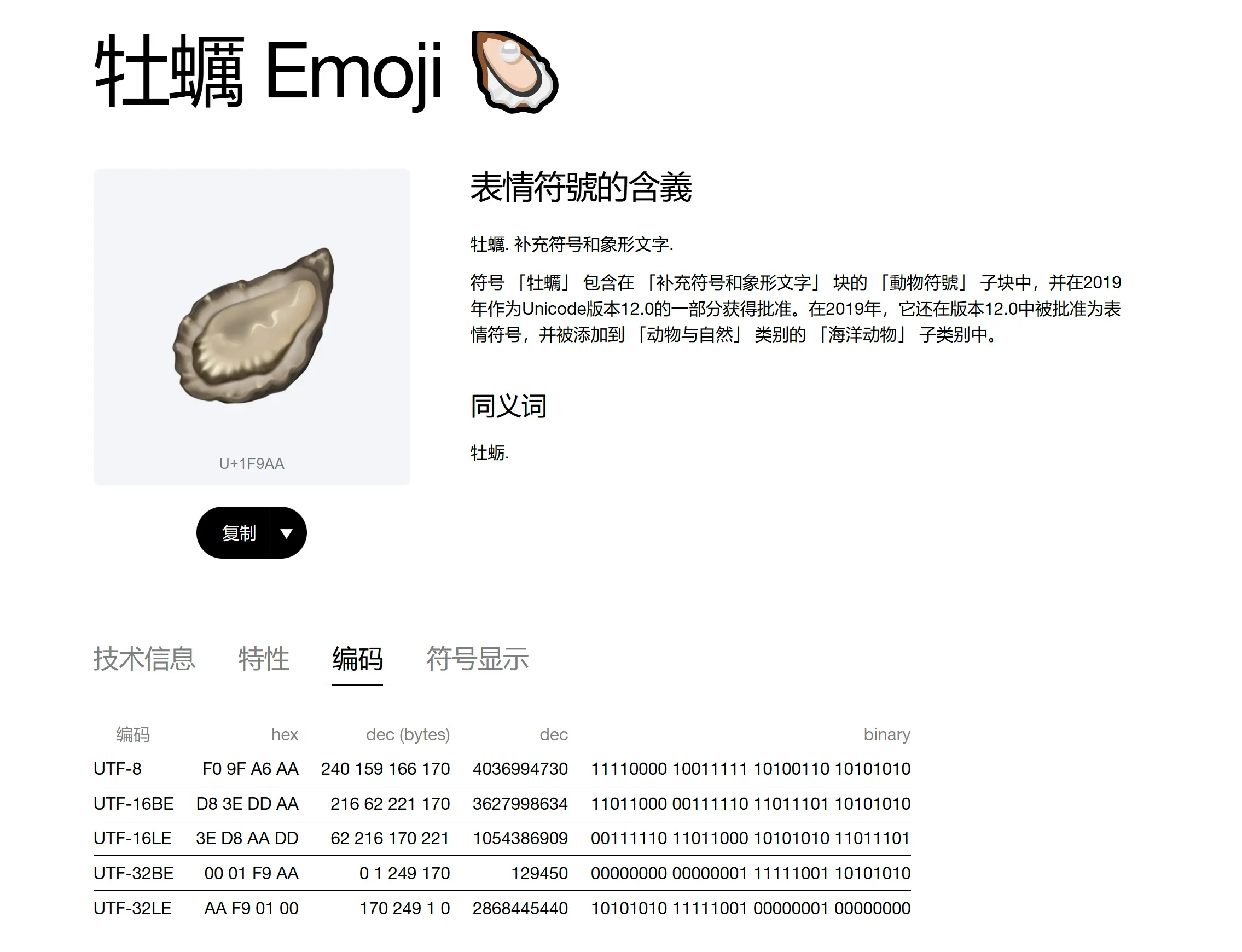
UTF-8 每个字符长度为 8 位的倍数,UTF-16 每个字符长度为 16 的倍数,UTF-32 每个字符长度为 16 的倍数。
Python、Rust 字符串内部存储采用 UTF-8。
.NET、Java 字符串内部存储采用 UTF-16。